

 Back in September 2017, an email address at my small scuba diving company Hero Divers began receiving unsolicited marketing emails from Ruben Harris, ruben.h@trekksoft.io, Product Marketing Manager at TrekkSoft AG.
Back in September 2017, an email address at my small scuba diving company Hero Divers began receiving unsolicited marketing emails from Ruben Harris, ruben.h@trekksoft.io, Product Marketing Manager at TrekkSoft AG.
As far as I can tell, he’s a legitimate employee & has a ZoomInfo profile.
Most of Ruben’s emails have a customized subject (i.e. “About Hero Divers”) & he mentions Hero Divers throughout the email, so it looks like a personalized email marketing campaign. The links in Ruben’s emails redirect through a link-tracking service & end up here:
https://www.trekksoft.com/en/lp/simple-sp-demo-request?utm_campaign=scubadiving2018&utm_source=email
Here’s the first email I received from Ruben Harris from 9/20/17:
Hi,
I’m writing you in the hopes of finding the person that is responsible for online marketing at Hero Divers. How are things going at Hero Divers? Do you find you are stretched this season?
I work with TrekkSoft, a booking solution for companies like yours. We provide you an integrated booking solution that automates your web, front desk and partner bookings. In plain English, we cut down on phone calls and emails while driving you more bookings through our distribution channels.
Have a look at what we can offer Hero Divers. Now is a great time of year to understand where you can make improvements. I’d be delighted to review your website and your operations to see if we can come up with some improvements together.
If there’s anyone else at Hero Divers that would be better to talk to, I would greatly appreciate it if you could point me in the right direction.
Kind regards,
Ruben Harris
Product Marketing Manager at TrekkSoftPS: We’ve got a large amount of clients worldwide, which would be ideal to cross sell with through the partner network we’ve set up.
There’s no remove link on any of his emails. I continued to receive similar TrekkSoft emails from Ruben at about one per week: on 9/25, 10/1, 10/6, & 10/12.
I just assume Ruben will get bored after awhile & stop emailing. Sure enough, the weekly barrage stopped after 10/12. But get an axe, it was a trick.
March 9th, what pops up? Another fucking email from Ruben Harris at TrekkSoft. He has the gall to pretend like we don’t have any prior history: “Hi, I’m Ruben from TrekkSoft. I came across Hero Divers online and wanted to get in touch to see if your team is thinking about options for an all-in-one booking system ….”
March 13th, it’s Ruben again: “Hi, just checking in to see if you wanted to ask any questions about TrekkSoft booking software ….”
I reply that I’m not interested.
March 18th, more from Ruben, “Just checking in to see if you had any questions about TrekkSoft for Hero Divers ….”
I reply again asking to be removed.
March 22, Ruben Harris at it again: “Quick question: as scuba diving company, what’s the biggest challenge for Hero Divers right now? ….”
March 26, yet another email from Ruben: “It’s Ruben from TrekkSoft. I’m writing to see if you’d seen my last message and to quickly pass on our Travel Trends Report 2018 ….”
March 30, yep: “Hi, I hope you found my last few emails useful. I also wanted to offer you a time slot to discuss Hero Divers properly and find out whether TrekkSoft’s all-in-one booking software could be a good fit for you ….”
Replied yet again asking to be removed.
April 3, “Hello, just wondering if you found the time to read through my emails over the past few weeks. If you are not interested in what our software can offer Hero Divers then I won’t mail you again ….”
Yes Ruben, I read your fucking emails. And if it’s true what you say that you won’t email me again, thank fucking god. Although by now, I’m mad.
I would never do business with TrekkSoft, even if I was interested. Ruben, either run a legitimate mass-marketing campaign & include remove links, or run a personal one & remove people when they ask.
I do a little research. Apparently I’m not alone. I find this from “The Stranger” on Twitter from 2016:
https://twitter.com/rivenworld/status/691033252908371968?lang=en
April 3, I post on the TrekkSoft Facebook page complaining about all these Ruben Harris emails & asking if he really worked as Marketing Manager for the company.
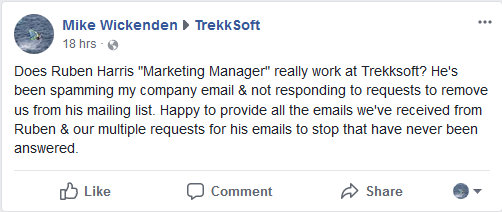
Next day I go back to the TrekkSoft Facebook page & my post is gone. Looks like they’ve hidden my post with no reply. Now I’m the angry non-customer.
April 4, I post again on their Facebook page:
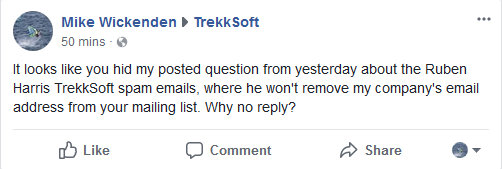
April 5, no reply from TrekkSoft. At least my comment is still up on their Facebook page. Facebook indicates TrekkSoft “usually replies within an hour”, but it’s been 2 days & counting with no reply to my Ruben Harris spam complaint.
I did some more digging & found out Quickmail.io is the link tracking service Ruben is using. They have a very helpful abuse reporting page, so I sent in a spam abuse complaint about TrekkSoft with copies of all the spam emails & my requests back to be removed. Really hoping they shut Ruben down.
TrekkSoft is a marketing company. It’s ironic how badly they are screwing up their own marketing & reputation with this shitty Ruben Harris email campaign. I also sent a direct message to VP of Sales at TrekkSoft with my complaint & a link to this blog. Maybe he’ll care.
Stay tuned.
 I discovered several illicit websites have been scraping, reprocessing & re-serving copyright web content from CarComplaints.com in real-time.
I discovered several illicit websites have been scraping, reprocessing & re-serving copyright web content from CarComplaints.com in real-time.
 Found this bot accessing the site via lots of different 202.46.* IPs. Reverse DNS points to ptr.cnsat.com.cn.
Found this bot accessing the site via lots of different 202.46.* IPs. Reverse DNS points to ptr.cnsat.com.cn.

